
 Shai Greenberg
Shai Greenberg
In this first post in a new series, we introduce Presto and show how to use it to combine data from several sources (S3, MyQL, Cassandra, Elasticsearch, etc) using Presto's Query Federation feature.
In this series of blog posts we will highlight various features and use-cases of Presto, a BigData-era query engine. We will show some of its cooler capabilities to help you make the most of it. If you have at least a basic familiarity with SQL and traditional databases - you have what you need to read on.
Presto is a distributed, scalable, open source SQL query engine with support for querying many data sources.
Let's break this down:
"Distributed" means Presto can divide queries to several (or many) sub-tasks and execute them on parallel on separate machines.
"Scalable" refers to the elasticity of Presto. Thanks to the way queries are being executed (in parallel on multiple machines) it is easy to meet increasing demand for resources, or letting go of resources when they are no longer needed. An indication of its scalability is evident in the fact Presto has been field tested on enormous scales (such as at Facebook, where it was originally developed) and has a rapidly expanding user base.
"Open Source" means it's being developed collaboratively and publicly by a community, it's sources are available to all and it can be used by anyone. Like many open-source software products, there is a commercial entity behind it to offer developer- and production-support and many additional features. In Presto's case that company is Starburst Data, and we at BigData Boutique are proud partners and offer Starburst-backed services for Presto users.
Query Federation
More often than not, organizations use many database and storage systems to store their data, not just a single one. Relational databases (MySQL, SQL Server, Postgress etc) for relational data and OLTP use-cases, Cassandra and other key-value stores for fast access to data by keys, and object storage systems like S3 and HDFS for storing large amounts of data cheaply.
One of the challenges of creating and maintaining Big Data systems, is accessing data when it is stored in so many places. Presto allows querying relational and non-relational databases (such as MongoDB) as well as objects stores (such as S3) via SQL, allowing for easier access to your data from BI tools and your own code. In fact, this is something new that Presto brings to our set of tools. Joining data from multiple data sources, in a single query, and at great performance - is something no tool was able to do before.
In this post, we'll discuss the ability of Presto to query multiple data sources in a single query, which in the context of Presto is referred to as Query Federation. Consolidating data from different sources used to be a long, tedious process - you would need ETL processes to bring data together into a shared format. Presto allows you to query data from several data sources both offline and interactively, all while using standard SQL as your query language, and parses your query into the relevant operations required by each source and the consolidation operation.
Example Scenario
Say we have data relating to flights arrival and departure, stored on S3 and typically accessed using Hive Metastore. This is a typical architecture for keeping tabular data on S3.
Consider that the customer is building a dashboard to display this data visually to managers or to employees at their operations department. The dashboard should help determine the points of origin with the longest delays during departure. For that purpose, a simple SQL statement using presto can return the percentage of flights for which the departure was delayed for more than 15 minutes, per airport:
use hive.training;
SELECT f.origin AS airport, COUNT(*) AS flights, cast ( SUM(depdel15) as DECIMAL(13,3))/COUNT(*) AS per15
FROM hive.training.flights_orc f
GROUP BY f.origin
HAVING COUNT(*) > 100
ORDER BY per15 DESC
LIMIT 10;
The results:
airport | flights | per15
---------+---------+-------
SOP | 319 | 0.376
OTH | 6495 | 0.351
ADK | 1318 | 0.346
UST | 345 | 0.330
CEC | 12563 | 0.291
MTH | 128 | 0.281
PBG | 294 | 0.279
MVY | 819 | 0.269
ACK | 4380 | 0.256
DUT | 6336 | 0.250
(10 rows)Unfortunately, the data stored on S3 only has the airport codes, but not the names. That is somewhat cumbersome and won't do for our customer, so naturally we want to add the names into the query. The names are available on a separate database - say, a MySQL database. Classically we would have to extract that data into S3 and then write the query as a join in Hive. However, Presto can join data from S3 and MySQL, and allow us to write an SQL query like the one below, as though they weren't completely different data sources:
use hive.training;
CREATE VIEW delays AS
SELECT a.name AS airport, COUNT(*) AS flights, cast( SUM(depdel15) as DECIMAL(13,3))/COUNT(*) AS per15
FROM hive.training.flights_orc f
JOIN mysql.public.airports a ON f.origin = a.code
GROUP BY a.name
HAVING COUNT(*) > 100
ORDER BY per15 DESC
LIMIT 10;
This, of course, is a simple example that attaches metadata to tabular data, but consider the implications of not having to maintain costly operations for bringing together transactional data sources, for instance. That would be of benefit even if the result is required for further ETL processes.
Another thing to note here is that we persisted the result of this join query as a "view", which is in-fact a new table on S3. It can now be queried in different ways and since it's a much smaller data set of the aggregated result, it will be faster to query because it doesn't need to recompute the entire aggregation from scratch.
Dynamic Filtering
Presto is quite a magnificent piece of work. There is a lot of really interesting pure Compute Science and algorithmic optimizations at work under the hood, which in turn drives Presto's amazing performance for many use-cases.
In general terms, presto takes the query and parses it into its own internal representation, for which it then creates a plan. That plan can be assigned to "Workers" which may run in parallel and possibly collect data from several sources, or run on different parts of the data. A cost-based optimizer uses statistics from the different databases to create the plan.
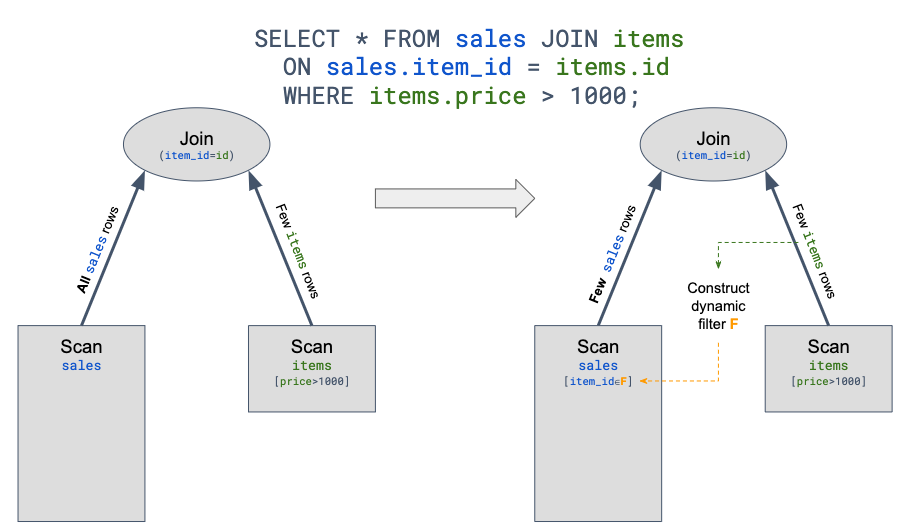
One such optimization is Dynamic Filtering. A full explanation can be found on this blog, but the general concept is that Presto can determine if one data-source is significantly smaller than the other, and use that fact to dynamically filter and skip scanning of irrelevant data on the larger source. This, in turn, leads to significant performance improvements in some use-cases while joining data from different data sources.
So not only is Query Federation possible; sometimes it's even faster than alternatives (such as a two-phase query).
The Setup
While we won't go into the details of setting up your presto cluster (though we could certainly help you with that - contact us), here are the basics of how to configure Presto to allow queries across various data sources.
Each platform is exposed as a "catalog" in the SQL syntax. For Hive, databases are mapped as schemas within the hive catalog, and tables are mapped as tables within those schemas. When writing a query that accesses tables from two data sources, we need to use the fully qualified name for each table that includes catalogs, schemas and tables - in the example above, they are "hive.training.flights_orc" and "mysql.public.airports"
Catalogs are registered by creating a catalog properties file, also referred to as a "connector", in the presto connector directory (typically /etc/presto/catalog).
So, for instance, a connector to hive over AWS s3 data can be configured in the hive.properties file in that directory, and may look like this:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083
hive.s3.aws-access-key=
hive.s3.aws-secret-key=
hive.allow-drop-table=true
hive.time-zone=UTC
hive.metastore-cache-ttl=30s
hive.metastore-refresh-interval=10s
Notice that this configures the location of the metastore service as well as the S3 access. S3 access can also be defined separately if Presto is installed on an AWS EC2 instance, by giving the instance the required permissions.
Similarly, a connector to MySQL can be configured in the mysql.properties file:
connector.name=mysql
connection-url=jdbc:mysql://localhost:3306
connection-user=(your username)
connection-password=(pwd)
After creating or changing each of the files, the Presto server needs to be restarted:
sudo service presto restartThat's it. There's no additional configuration to being able to consolidate data from different sources, other than defining access to them.
You can define connectors that work with many other types of data sources such as Glue, Kafka or Mongo, and also connect to multiple instances of the same data source.
In the next post we'll look at using Presto with AWS Glue.
We build modern Data Warehouses and Data Lakes that are cost-effective and scale easily. Interested in learning more? Contact us



Comments are now closed