
 Shai Greenberg
Shai Greenberg
In this post, we dive into the most common use case of exploring and managing data located in an S3 object storage, using Presto and schema data stored on AWS Glue.
In the previous post we introduced Presto and discussed its query federation feature, going into an example of joining data from several different data sources. The most common use-case for Presto, however, is making interactive SQL queries on object-storage systems like S3, HDFS and Ceph possible. What used to be a slow process far from being viable for performing analytics queries, is now made possible with Presto without requiring long-running batch jobs or keeping the data in a costly relational database. In this post, we are going to go back to basics and discuss that.
Probably the most well-known technology designed and built for querying object-storage systems is Apache Hive. As a matter of fact, Presto was built as a replacement for Hive by a team of engineers at Facebook who wanted a high-performance engine (as opposed to Hive's long running time) that could "speak" standard ANSI SQL (as opposed to HiveQL, which is "not quite" SQL). Presto acts as a full replacement for Hive, giving full access to SQL queries on any object-storage from all popular BI tools, via JDBC and ODBC connections.
What follows is a walk-through of an Object Storage use case, in which we'll query an S3 bucket containing data from OpenStreetMap, a popular mapping service. We will do some exploratory analysis on the dataset and then transfer it to our own S3 bucket.
OpenStreetMap
OpenStreetMap (OSM) is a popular mapping service. Even though many sites and applications use OSM, the mapping service you are probably more familiar with is Google Maps. The difference between the two is that the data in Google Maps is owned by Google, and OSM data is free to use (as long as anything derived from it is also free to use). This allows for developing some use-cases and derived data sets, and it is a perfect match for what we are about to do.
We will show how to configure Presto to query data from OpenStreetMap on AWS S3 as part of an exploratory analysis. We will then show how to perform an ETL process with Presto from OSM into a different S3 bucket, in case you need that data accessible quickly later.
AWS Glue Setup
Apache Hive is actually made of two parts - the computation engine itself (let's call it Hive), and the metastore part, where the schema for the data is kept separately from the data itself (let's call it Hive Metastore - or HMS). This is the same for Presto, which, in fact, uses HMS for keeping tab of schemas for data stored on S3, HDFS, and so on.
Just to make sure we are being very explicit about this and avoid a common misconception - Presto is relying on Hive Metastore only, it doesn't use Hive - the computation engine - at all.
AWS Glue is the AWS parallel to Hive Metastore, and can be thought of as a hosted and managed version of Hive Metastore - and it maintains the schemas for your data in S3. Presto can use AWS Glue in the same way it uses HMS, and we often recommend that to customers who are hosted on AWS instead of deploying and managing their own HMS.
After you've set up your Presto cluster (contact us for the optimal way to do that), you need to add a catalog file to the catalog directory (say as glue.properties). Check out the previous blog post if you are not sure how:
connector.name=hive-hadoop2
hive.metastore = glue
hive.non-managed-table-writes-enabled = trueAs you can see the glue catalog is actually using the Hive connector, only signaling it to use AWS Glue and not a self-managed HMS. The last line allows writing to the S3 buckets that we'll set up later in this post.
Permissions for Glue will be checked for the user running the operations. The additional permissions required for the instance for this use case are for the S3 bucket osm-pds :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::osm-pds",
"arn:aws:s3:::osm-pds/*"
]
},
{
"Effect": "Allow",
"Resource": "*",
"Action": [
"glue:*"
]
}
]
}Once you've restarted Presto so it's brought up to speed with the catalog update, you are ready to create tables in Glue and query them. Before that, however, let's make this analysis a little bit easier by using a GUI client.
Outside Access via JDBC
Presto exposes a JDBC interface that allows you to query it from various tools. By default, you'll have to have port 8080 exposed to the machine from which you're running the client. In AWS EC2, this can be done by attaching a matching security group to the instance.
You can choose whichever client is convenient to you that can connect to a Presto JDBC interface. A good choice is DBeaver, as it comes out of the box with a Presto connector.
The host in the connection setting is the address of your presto server, and the default port is 8080.
Exploratory Analysis
Now that we've got a working client, let's start looking for our recycling containers. At first we need to set up the schema in Glue:
CREATE SCHEMA glue.osm;
CREATE TABLE glue.osm.osmplanet (
id bigint,
type varchar,
tags map(varchar, varchar),
lat decimal(9,7),
long decimal(10,7),
nds array(row(ref bigint)),
members array(row(type varchar, ref bigint, role varchar)),
changeset bigint,
timestamp timestamp,
uid bigint,
user varchar,
version bigint
)
WITH (
external_location = 's3://osm-pds/planet/',
format = 'ORC'
)This tells Presto to create a table with the above schema data in Glue, which refers to the OSM planet data bucket. In this case I've provided the schema structure. However when the structure is unknown, one can use a Glue Crawler to get the schema from the existing data.
For this example, we will look for information about recycling containers of several types that are in Israel. Since we're not really sure about how to access what we're looking for, some exploration is necessary first.
Let's look at a limited result set. Specifically we'll try and get all the data that's within a bounding box that's around Israel. If you query for a count of the number of records with and without the bounding box, you will see that there's a sizable difference.
SELECT *
FROM osmplanet
WHERE lat BETWEEN 29.5013261988 AND 34.2654333839
AND long BETWEEN 33.2774264593 AND 35.8363969256
LIMIT 10;From the results, we can understand the basic structure of the data: each row is an entity on the map (a node, or a building, for instance), with latitude and longitude to determine its location, and further information stored in a map of tags. Since we (most likely) got results with an empty map of tags, what we want is to get results that have actual data in that field.
For that, we'll consult the Presto documentation on map functions, which shows us how to check for an empty map:
SELECT *
FROM osmplanet
WHERE lat BETWEEN 29.5013261988 AND 34.2654333839
AND long BETWEEN 33.2774264593 AND 35.8363969256
AND tags <> map()
LIMIT 10;At this point, we can start seeing what kind of information is stored in the tags and what we should look for, in order to query it, DBeaver also shows the tags for a selected row in the results.
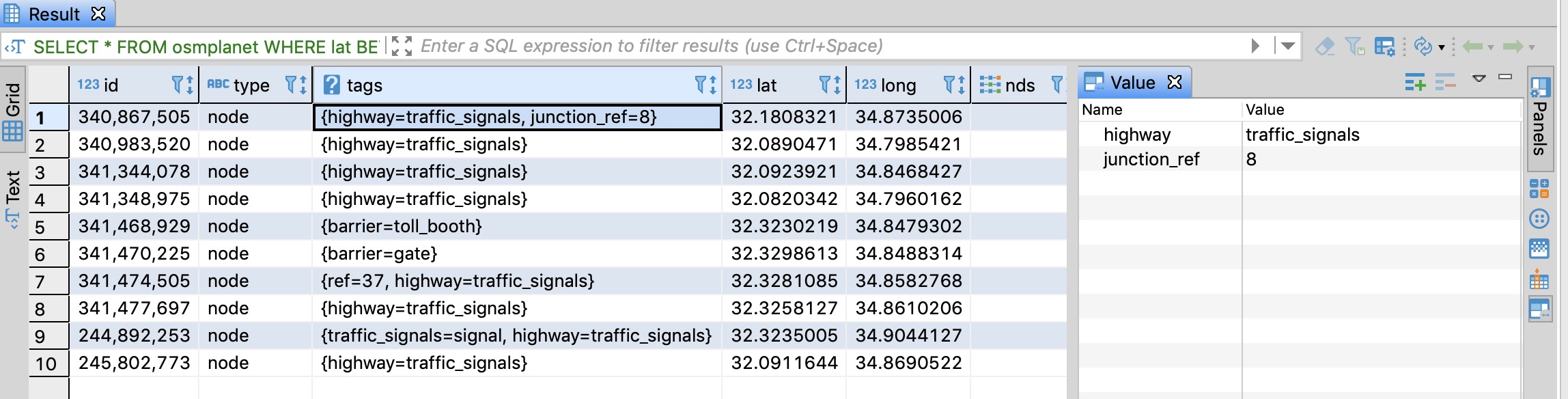
Recycling locations in OpenStreetMap use the tag amenity:recycling, which we will now filter the query with:
SELECT *
FROM osmplanet
WHERE lat BETWEEN 29.5013261988 AND 34.2654333839
AND long BETWEEN 33.2774264593 AND 35.8363969256
AND element_at(tags, 'amenity')='recycling'Investigating further will lead us to see that the containers are under a tag called "recycling_type" and that the various types of recycled materials are represented by other tags. A query that returns the required information would look something like this:
SELECT id, lat,long,
element_at(tags, 'recycling:plastic_bottles') as plastic_bottles,
element_at(tags, 'recycling:glass_bottles') as glass_bottles,
element_at(tags, 'recycling:clothes') as clothes,
element_at(tags, 'recycling:small_appliances') as small_appliances,
timestamp,
user
FROM osmplanet
WHERE lat BETWEEN 29.5013261988 AND 34.2654333839
AND long BETWEEN 33.2774264593 AND 35.8363969256
AND element_at(tags, 'amenity')='recycling'
AND element_at(tags, 'recycling_type')='container'
AND (element_at(tags, 'recycling:plastic_bottles')='yes'
OR element_at(tags, 'recycling:glass_bottles')='yes'
OR element_at(tags, 'recycling:clothes')='yes'
OR element_at(tags, 'recycling:small_appliances')='yes')Move data to a separate bucket
Aside from dynamically querying the data, if there's a subset of the data which we know we want to analyze even faster we can move it to a separate bucket.
At first we need to create the new bucket via S3. Remember that you also need to give permissions to the instance to query and write into it. Once the bucket is created, all we need to do is create a schema with the name of the new bucket, and then insert the results of a query into a table in that schema. The double quotes are required in this specific example, since the name contains a hyphen.
CREATE SCHEMA glue."bdbq-osmplanet"
WITH (
location = 's3://bdbq-osmplanet/recycling'
);
CREATE TABLE glue."bdbq-osmplanet".containers
WITH (
external_location = 's3://bdbq-osmplanet/recycling',
format = 'ORC')
AS ( SELECT id, lat,long,
element_at(tags, 'recycling:plastic_bottles') as plastic_bottles,
element_at(tags, 'recycling:glass_bottles') as glass_bottles,
element_at(tags, 'recycling:clothes') as clothes,
element_at(tags, 'recycling:small_appliances') as small_appliances,
timestamp,
user
FROM glue.osm.osmplanet
WHERE lat BETWEEN 29.5013261988 AND 34.2654333839
AND long BETWEEN 33.2774264593 AND 35.8363969256
AND element_at(tags, 'amenity')='recycling'
AND element_at(tags, 'recycling_type')='container'
AND (element_at(tags, 'recycling:plastic_bottles')='yes'
OR element_at(tags, 'recycling:glass_bottles')='yes'
OR element_at(tags, 'recycling:clothes')='yes'
OR element_at(tags, 'recycling:small_appliances')='yes')
);
Summary
We have walked through a standard and very common use-case of using SQL for querying data stored in object-storage system, and demonstrated specifically how this could be done using AWS Glue as the Metastore. We have also shown how Presto can be used as an ETL tool for moving data around, or creating "views" - similar to how you'd work with any SQL database technology - except in this case the separation of compute and storage makes your life easier, and total cost of operation cheaper.
Other than billing and performance considerations, we've actually already discussed another important feature of Presto - and that's Query Federation, which can serve you if you're unifying or joining data between several data sources. By using Presto, you're also avoiding the vendor lock-in, which is integral to choosing a managed service.
On the other hand, you won't be missing out on support - the people at Starburst Data offer continued support for Presto and continually introduce new features into both a community edition and a licensed Enterprise edition, and as their partner we at BigData Boutique will gladly help you to get started - all you have to do is contact us.



Comments are now closed