
 Jeovanny Alvarez
Jeovanny Alvarez
Incorrect configurations can lead to the infamous Elasticsearch split-brain problem. In this post we will discuss what the “split brain” problem is and how you can avoid it in your clusters.
Elasticsearch is a popular distributed search engine that is used by many organizations to handle large amounts of data. One of the main benefits of Elasticsearch is its ability to distribute data across multiple nodes, which allows for faster search and retrieval. However, this also introduces the risk of a split brain situation, which can have serious consequences for the integrity of the data.
What is a Split Brain Situation?
A split brain situation occurs when a distributed system, such as Elasticsearch, loses communication between its nodes. This can happen for a variety of reasons, such as network issues, hardware failures, or software bugs. When this happens, each node in the system may continue to operate independently, which can result in conflicting data being stored on different nodes.
The “split brain” problem in Elasticsearch refers to a situation where a cluster becomes “split” into two or more pieces. Each piece essentially becomes its own cluster that functions similarly to how the “whole” cluster did. Each cluster may continue to process search and indexing requests, resulting in duplicate or conflicting data being stored on different nodes.
There are a couple of issues that arise with this situation, however. To start with, each piece now has less resources to function because each of these subclusters has less nodes than the original cluster. But more importantly, the data between the clusters is no longer consistent. Since each piece is now functioning independently of the others, they do not share the same cluster metadata and will not receive the same cluster state changes. The image below depicts what happens when the “split brain” problem occurs:
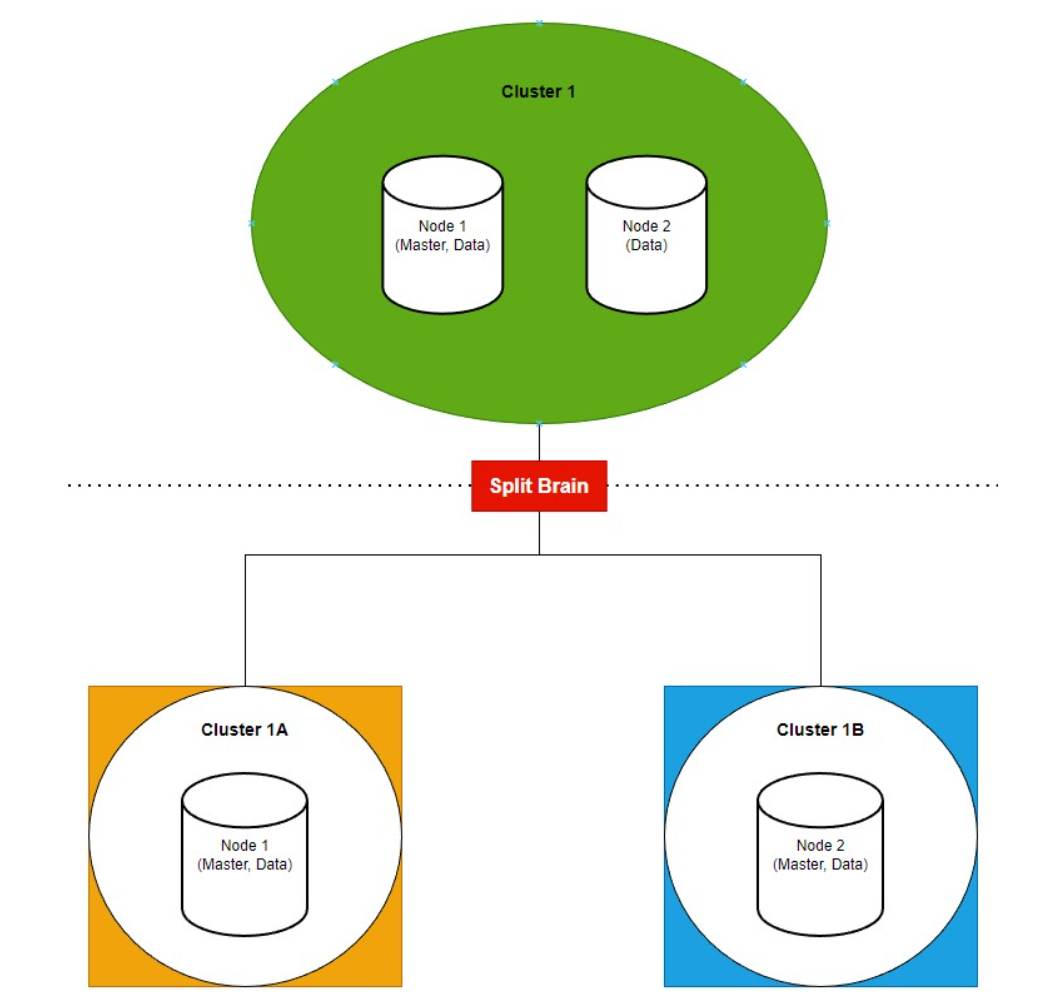
As you can see in the image, Cluster 1 is a small two node cluster with Node 1 functioning as the master node and as a data node and Node 2 functioning as a master-eligible data node. Suddenly an issue occurs such as a networking error or other failure that prevents the two nodes from communicating with one another for an extended period of time.
This causes the “split brain” problem to occur. Node 1 continues to act as the master node and functions independently as it attempts to reconnect with Node 2. Node 2 on the other hand, finds that the original master node, Node 1, has gone down so it decides it must take its place and become the master node. It continues to function independently as well which causes the two nodes to get out of sync and have inconsistencies with the data held in each node.
Consequences of a Split Brain Situation
The consequences of a split brain situation can be severe, especially in the case of Elasticsearch. Duplicate or conflicting data can cause inconsistencies in search results, which can lead to incorrect or incomplete information being presented to users. This can damage the reputation of the organization and lead to lost revenue or customers.
In addition, a split brain situation can lead to data loss or corruption. If two nodes simultaneously update the same document, one of the updates may be lost or overwritten when the network partition is resolved. This can result in data inconsistencies or even permanent data loss.
How to Prevent a Split Brain in Elasticsearch
Preventing a split brain situation in Elasticsearch requires careful planning and configuration. There are several approaches that can be used to prevent or minimize the impact of a split brain situation.
Correct quorum-based configuration
Elasticsearch uses quorum-based decision making amongst its master-eligible nodes. All of the master-eligible nodes within the cluster must “vote” on electing a master node and when changing the cluster state, and a majority of nodes must agree on the state of the cluster before any updates are allowed.
A quorum-based majority must be reached when this vote occurs in order for the cluster to reach a decision and maintain a healthy state. A quorum is defined as (n/2)+1 nodes, where n equals the total number of master-eligible nodes in the cluster.
For this to work, you need to maintain at least 3 master-eligible nodes in your cluster (where the quorum will then be defined as 2 master-eligible nodes). Any cluster with 2 master-eligible nodes is guaranteed to have a split-brain at some point.
In versions prior to 7.0 of Elasticsearch, you need to configure a minimum number of master nodes using the minimum_master_nodes setting in the elasticsearch.yml configuration file. This is the number of nodes required for a quorum, as explained above.
Later versions (7.0 and above, including OpenSearch) use a list of seed hosts using the discovery.seed_hosts setting. This setting allows you to configure the domain of each of the master-eligible nodes that will be searched for during the discovery process. The discovery module has been completely redesigned in 7.x and above and discovery.zen.minimum_master_nodes is no longer used.
Dedicated master nodes
For Production environments, it is recommended that you maintain a minimum of three master-eligible nodes, and preferably that they be dedicated master nodes (to read more about why you should use dedicated master-only nodes, check out this post). All nodes in Elasticsearch are master-eligible by default, so they would need to be explicitly configured otherwise to remove the eligibility.
Voting only nodes
Another approach for maintaining proper quorum on smaller clusters is to define data nodes as voting-only nodes. The voting-only mechanism allows data nodes, which are usually busy handling heavy requests and operations, to be considered for forming a quorum and voting, while not running the risk of having them elected as active master nodes. Read more about this role here.
Avoid improper Network Configurations
Proper network configuration is also important in preventing split brain situations. Nodes should be connected through reliable and redundant network connections, and network partitions should be detected and resolved quickly.
But even more important, avoid changing some risky configurations like discovery.zen.ping.timeout, which defaults to 3 seconds. If you had to change this configuration, in all likelihood your deployment or setup are incorrect.
Use a recent Elasticsearch version
Some Elasticsearch versions, especially older versions, are susceptible to various bugs that expose them to instability and sometimes also to the split-brain problem. Don’t be at risk, make sure you upgrade your Elasticsearch cluster to the latest version available, or at least 7.x and beyond.
Detecting and recovering from a split brain situation in Elasticsearch
The fastest and easiest way to detect that something is wrong is monitoring your cluster to make sure the number of nodes in it stays the same and doesn’t suddenly drop or change significantly. If two nodes in a cluster are reporting a different composition of the cluster, it is a telltale sign that a split-brain situation has occurred.
If you act quickly once a split-brain problem is detected, you could have a chance to save your cluster. You could apply a cluster write block to avoid any data conflicts from being created, and then work on resolving the cluster state by trying to merge the nodes together.
In case you weren’t lucky enough to act fast, most likely this is a lost cause. You can still try merging the nodes together into a unified cluster, but then you run the risk of the cluster not being able to resolve existing conflicts in both state and data.
You have a better chance at programmatically reindexing both split clusters into a new, larger cluster. We strongly discourage manually tempering with the data folders on disks.
Conclusion
The “split brain” problem in Elasticsearch can pose a serious problem that can lead to data integrity issues if left unresolved. It can be averted fairly easily by modifying the Elasticsearch configurations to ensure the number of master-eligible nodes is enough to allow for quorum based decision making. If you’re unsure your cluster meets this standard, be sure to check it as soon as possible to prevent this problem from occurring.
If you’re looking for a deeper dive into cluster misconfigurations and/or best practices, be sure to check out our Pulse solution. Pulse can offer insights into your cluster with actionable recommendations. It also allows you to tap into world-class Elasticsearch experts to further review your cluster and help with your needs. If you’re interested in learning more, reach out to us here!




Comments are now closed