
 Itamar Syn-Hershko
Itamar Syn-Hershko
Apache Hudi introduced easy updates and deletes to S3-based Data Lake architectures, and native CDC ingestion patterns. Here is all you need to know about it.
Apache Hudi is a data Lake technology that has been in use since 2016. Originally built by Uber, Hudi is the first of the three data platforms that we’re going to examine in detail. The series has in-depth reviews of Delta Lake and Apache Iceberg, and will end with a comparison between those three popular technologies.
This is the third post in our series, Architectures Of A Modern Data Platform
In this post, we are going to provide an overview of Apache Hudi, before diving in and examining its key strengths and how they match up against the requirements we set out in our previous article.
A short history of Apache Hudi
Hudi was originally developed at Uber in the early 2010s and went into production in 2016. Uber had a requirement for a cloud-based data lake to power and manage the 100PB of data that underpin key business functions for trips, riders, and customers. Uber’s data engineering team had a specific need to feed changes from relational SQL databases via either change data capture (CDC) or binlogs into a data lake.
Uber submitted Hudi to the Apache software foundation in 2019, releasing it as Open-Source software and forming a community around it. Since Uber created Hudi, other large data-rich organizations like Walmart and Disney have adopted it as their primary data platform.

As covered in our introductory post, we aren’t trying to differentiate between data lakes or data warehouses. When implemented properly, their architectures are likely to be similar on multiple levels. Hence the term ‘data platforms’. With these modern architectures come a variety of fairly standard requirements, and we are going to evaluate how Hudi measures up.
The Challenges Hudi Solves
Hudi originated from the requirement to feed changes from traditional, relational SQL databases into a data lake platform for long retention and to support analytical queries at scale.
Uber faced challenges with their ever-growing data platform requirements, such as incremental data processing, data versioning, and efficient data ingestion.
At the core of the Hudi project is the capability to connect any relational database to a data lake storage layer such as S3 and HDFS via CDC or binlog, which are the standard ways of capturing data changes in various SQL databases. Since those change notification streams do not contain only append-events, but they can signal a row update or delete as well, this is not a trivial task.
During the years Hudi was conceived and developed, there were no other easy solutions to support data updates on S3 - users had to innovate ways to do it, and it was rather a difficult and rigorous task to do, and many just decided to avoid it altogether. That is why Hudi is so important, it paved the way for modern data lakes as we know them today.
Nowadays, any commonly used query engine supports querying Hudi tables - Trino, PrestoDB, Spark and more.
Common Apache Hudi Use Cases
Given Uber’s initial in-house development of Hudi, it addresses several use cases, some are niche but some are very popular, where there are gaps in traditional data warehouse and data lake platforms.
Real-time Data Ingestion
Hudi doesn’t quite provide real-time data ingestion, but it’s closer than other data lake platforms. Traditionally when ingesting data from OLTP sources, users require an array of tools to handle the sources in a timely fashion. Some Hudi functions (like Upsert for RDBMS) provide resource-efficient alternatives to bulk-upload ingests. Ultimately, it’s Hudi’s DeltaStreamer tooling that allows easy scale-out to include more and more sources.
Incremental Processing
Incremental Processing is an important use case as traditional data architectures often ignore data that arrives late. As the complexity of ETL pipelines increases, the more likely it is for processing and event times to deviate. Hudi deals with this issue by providing a dedicated table for consuming new data. A separate table is also used to reconcile any granular changes for individual reads. Thus, processing schedules can be significantly reduced to much shorter increments.
New Batch and Streaming Architecture
Hudi introduces data streaming principles to data lake storage, which allows data to be ingested significantly faster than traditional architectures. It also allows for the development of incremental processing pipelines (see above) which are hugely faster than traditional batch processing jobs. Additionally, because Hudi doesn’t require server resources up front, it provides greater analytics performance with less operational cost.
Schema Evolution
As we covered in our introductory article, the ability to ad-hoc alter the data schema is key. Hudi leverages Avro to dynamically alter table schemas, using schema on write. This is important for consistency as it ensures data pipelines don’t fall over as a result of failed backward compatibility from schema changes.
Updates and Deletes
As mentioned in our introductory piece, we believe that a modern data platform should provide robust support for updates and deletes even when data resides on a cheaper storage layer like S3 or HDFS. Luckily, Apache Hudi has both of the above.
Deletes
Hudi allows two types of deletes to be used in its tables for various compliance and privacy requirements.
The first is ‘soft delete’, which retains a record but sets the value of the data to null. Provided the fields you are seeking to delete can be set to null, as documented in the schema, this is a good option for standard deletes not related to privacy or compliance. Soft deletes can be rolled back using the record that is maintained.
‘Hard deletes’, on the other hand, are permanent deletes to erase any trace of the field from the table. There are three ways of doing this, using either DataSource and changing OPERATION_OPT_KEY; using DataSource and changing PAYLOAD_CLASS_OPT_KEY; or by using Delta Streamer and adding a new column indicating which records are to be deleted.
Updates
Hudi comes with two options when it comes to updating, which shouldn’t be used interchangeably as they behave very differently.
‘Insert’ is a fast operation that can be used to update or insert new values to records that are tagged. It is exceptionally fast and is best used in circumstances where you can tolerate multiple duplicates in a table. There is also a BULK_INSERT operation, which is a scalable version of insert capable of handling hundreds of terabytes of load.
‘Upsert’ is the alternative to insert, as is configured as the default in Hudi. It is largely the same as the insert operation, but it performs an index lookup before any updates. This is slower than insert but is better for storage optimization and rightsizing of files. This operation will not generate any duplicates.
Hudi’s Table Format
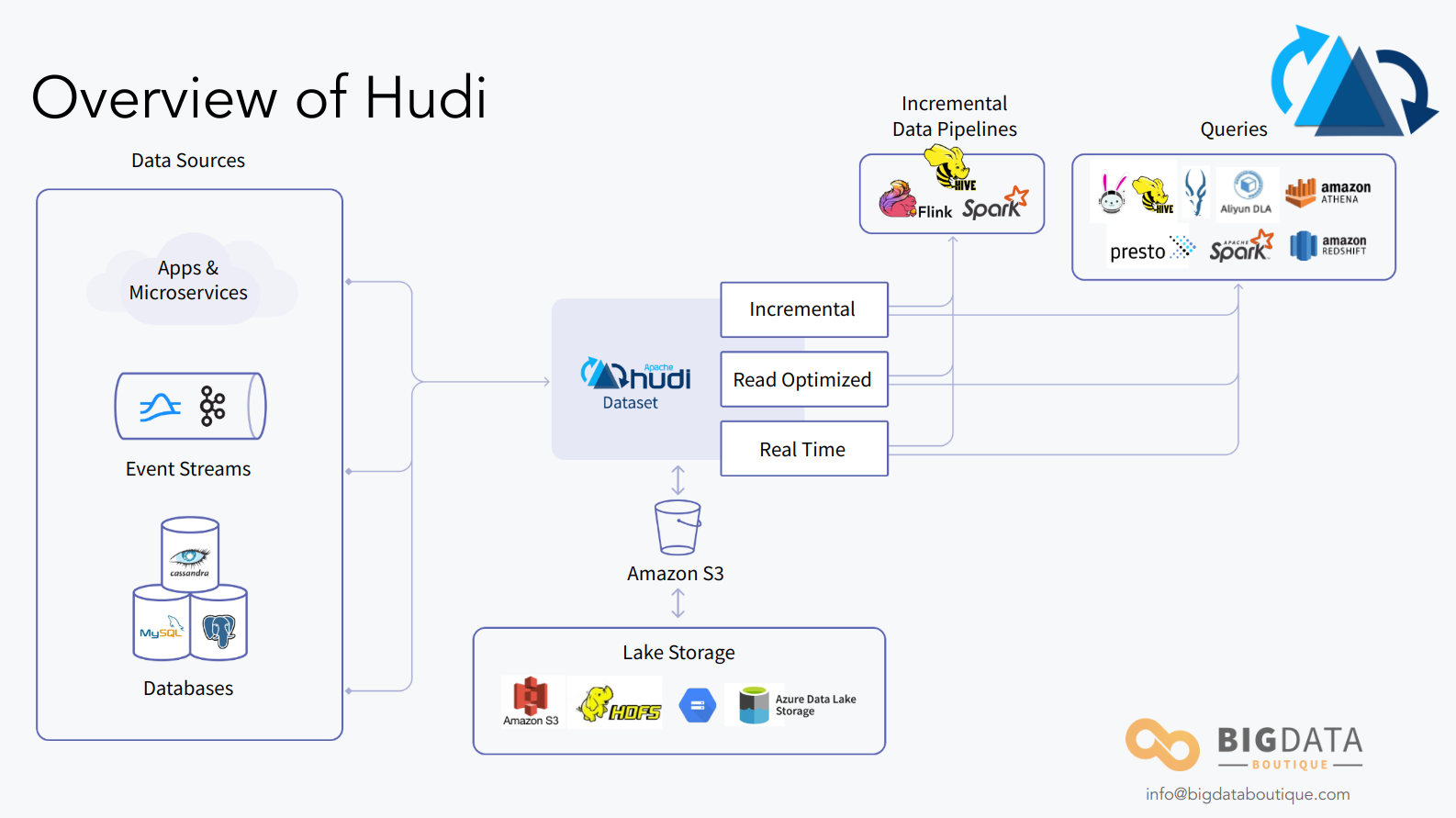
In order to support those use-cases and features, Hudi uses a similar partitioned directory structure to that of a traditional Hive table format but introduces the concept of a commit log, or a “timeline”, which allows it to do a lot more than what Apache Hive ever supported.
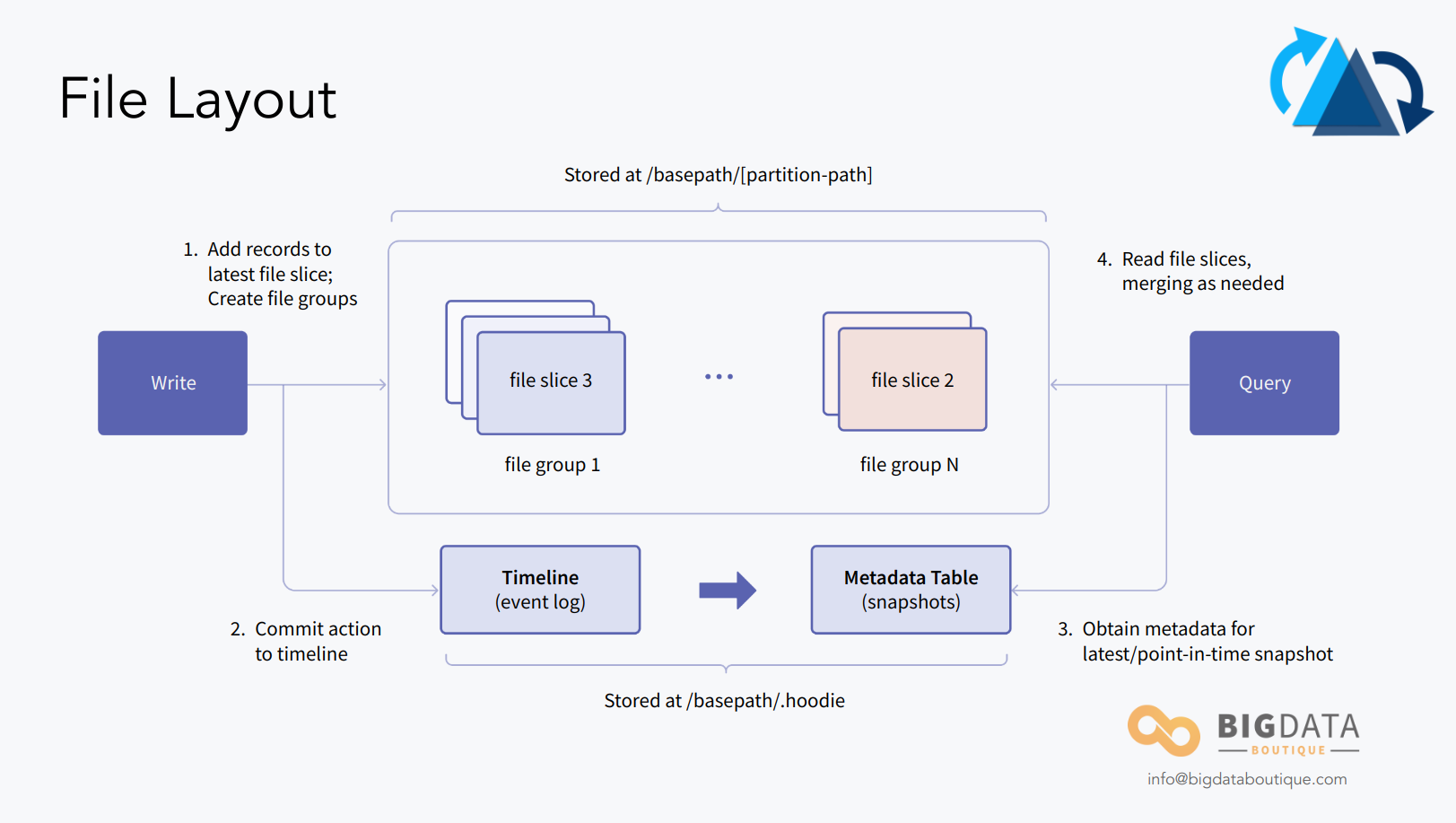
This table format and how data is being written to it are rigorously explained in the Hudi docs: file layout , writing path. What’s more important for us here is how this data is queried, and the different query types offered by Hudi.
Apache Hudi Query Types
Copy on write and merge on read are two different approaches to handling updates in data storage systems. With Hudi, you can choose whether to use a Copy on Write (CoW) or Merge on Read (MoR) on a table basis (“Dataset”), to optimize either reads or writes for any given table or use-case. Let’s see how that’s done.
Copy on Write
A Copy on Write is a strategy where data is not modified directly in place, but instead a copy of the data is made when a modification is requested. This ensures that the original data remains intact and can be used by other processes or users, but also means updates and deletes are applied during write. The updated data is written to the new copy of the data, and the old copy is discarded.
CoW should be used when there is a read-intensive workload in use, as well as data with a lower rate of change. Hudi defaults to CoW unless it’s manually changed to MoR. Every time that an update or delete is requested, a new version of the updated files is created in a write.
Merge on Read
Merge on read, on the other hand, is a strategy where data is updated on read time and not immediately reflected in the data on storage.. Instead, the updates are stored separately and are merged with the original data when it is read.
MoR is best suited to data with a high change rate, or write-heavy data. Unlike CoW, MoR uses a mix of Parquet and Avro data formats. Any data updates are logged at a row-level to allow for column updates. Hudi also creates two tables in Hive - one is optimized for reading and the other is a real-time view.
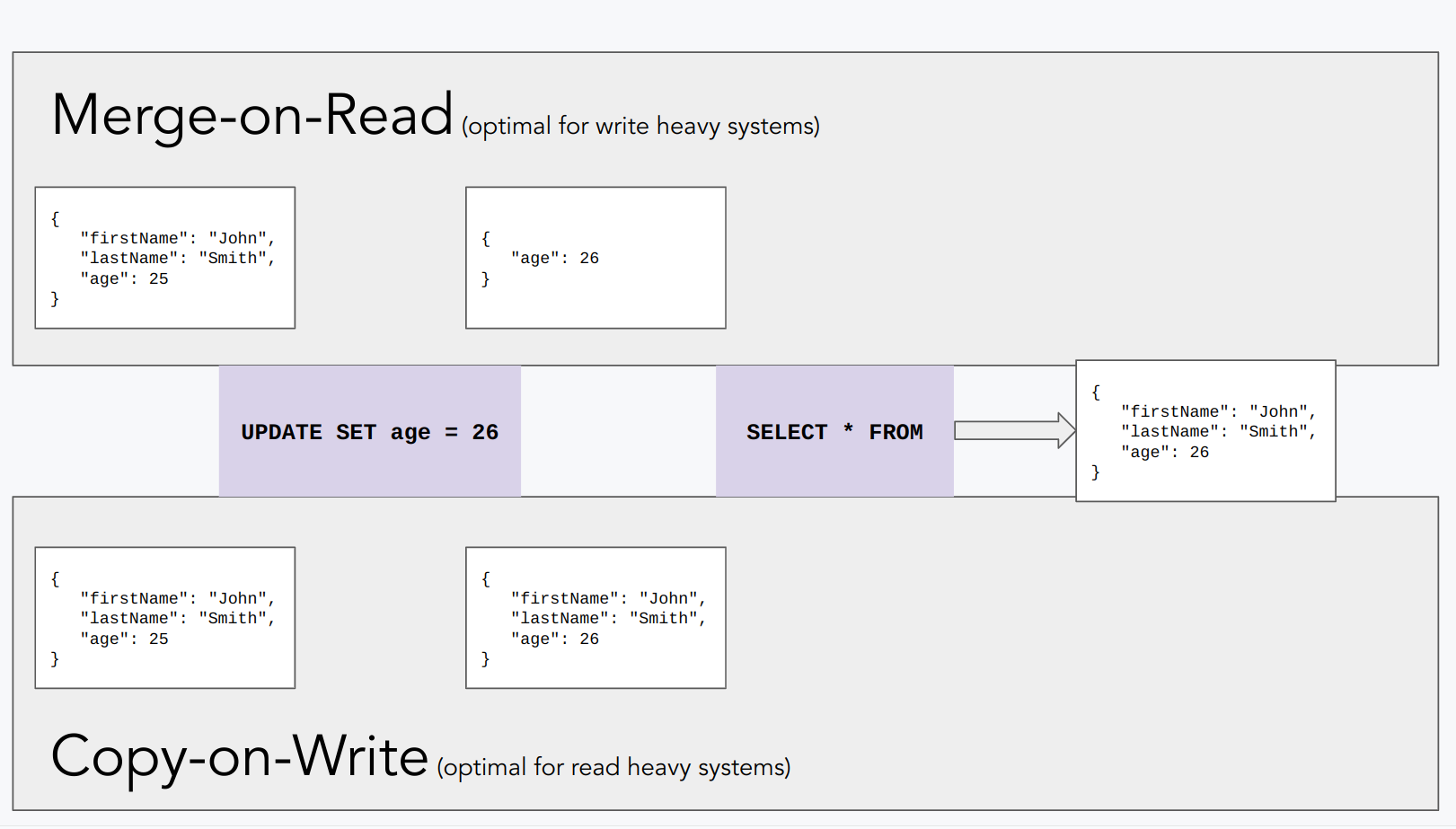
Hudi supports different query types to balance freshness of data and query performance. Merge on read will demonstrate higher write throughput but queries will have to work harder thus be slower. Copy on write will exhibit slower writes, but queries will not have to waste time doing extra work. Ingest speeds also matter for some use-cases, so assuming control over that is a great feature by Hudi.
Apache Hudi: A Stream-based approach
Hudi differentiates itself from other modern data platforms with its own ingestion tool called DeltaStreamer. This enables Hudi to ingest data from a variety of sources, whilst giving them shared capabilities. A unique capability of Hudi is that it allows you to manage data at an individual record level in object storage, whilst DeltaStreamer handles the ingestion. This makes CDC (Change Data Capture) and data streaming much more straightforward.
DeltaStreamer
DeltaStreamer sits separately from Hudi as a standalone function. It is capable of ingesting data from DFS, database change logs, and Kafka. It also has both one-off and continuous ingestion modes.
Run-once is an incremental pull of events and ingesting them into Hudi, and for MoR tables compaction is automatically enabled. Continuous mode creates an infinite loop of ingestion, the frequency of which can be configured. If you enable continuous mode, you must allocate appropriate resources as compaction and ingestion will be running concurrently.
Object Store Access
Because Hudi allows you to manage all of your data at a record level within object storage, it gives you a vast range of query tools and storage options. Hudi will read and write datasets on Azure Blob, Google Cloud Storage, or AWS S3. It also has specific inbuilt capabilities such as consistency checking on S3. It’s recommended to use Hive, Spark, Presto, or Flink to query Hudi data.
Apache Flink support
There’s no doubt that Flink has changed data processing and data architectures. It is both a processing engine and a framework for performing computations at in-memory speed over bounded and unbounded data streams. Bounded data streams have a pre-defined start point and end, whilst unbounded do not have a defined endpoint.
Where Hudi is concerned, Flink provides a stream processing engine that returns queries in close to real time. This is known as continuous queries.
Flink Continuous Queries
The introduction of Flink continuous queries to DeltaStreamer has built up a strong and unique capability. It allows users to perform stream analysis whilst data is ingested, and relies upon Hudi’s native CDC support in object storage. Any message changes in the data stream are retained and then consumed, which Fink then analyzes in real-time, which massively cuts down on latency in an ETL pipeline.
Summary
There’s no doubt that Hudi is a powerful tool that has set the scene for modern data lake and warehouse platforms. In the next posts in the series, we are going to look at other technologies which took inspiration from Hudi no doubt, and then evolved further.




.bigdataboutique.com/2022/08/architectures-of-a-modern-data-platform-aaw0xs){kind=link}
Comments are now closed